
E听说破解思路
真的不想再忍受E听说逆天的评判标准了,每次都才20出头🙁
所以便直接上手获取标准答案吧🙂
弯路
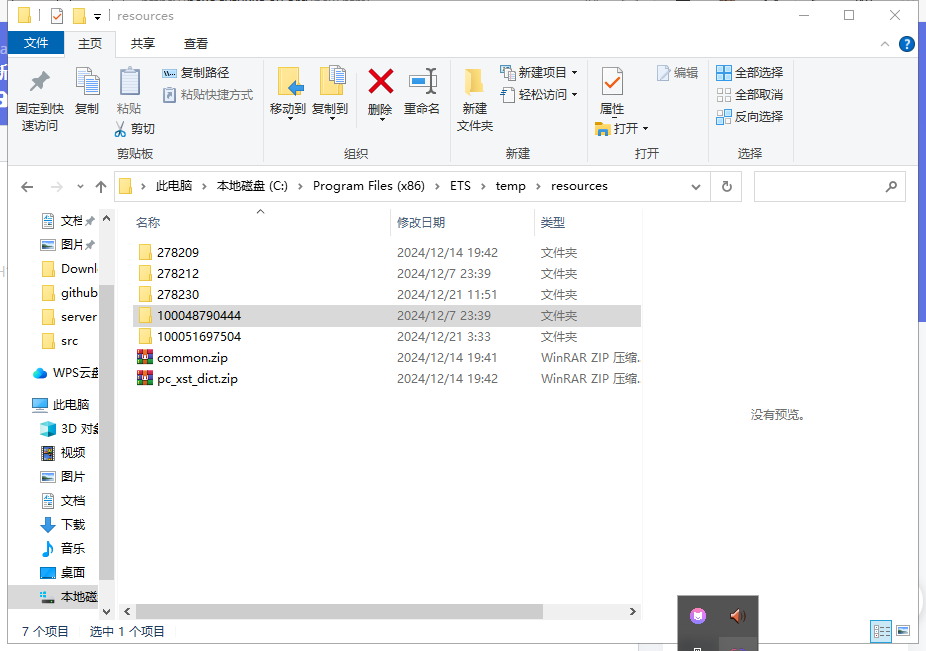
在一通折腾下,我找到了这个目录C:\Program Files (x86)\ETS\temp\resources,根据推测这个目录便是每次听说文件下载到的地方,但是内容不齐全,于是我便想试试听说文件的压缩包,但有密码,后面根据软件的日志,发现密码是base64,但实力有限,无法找到密码,也就告一段落了
偶然
一次偶然的发现,我发现在软件的缓存目录中发现了完整的解压后的文件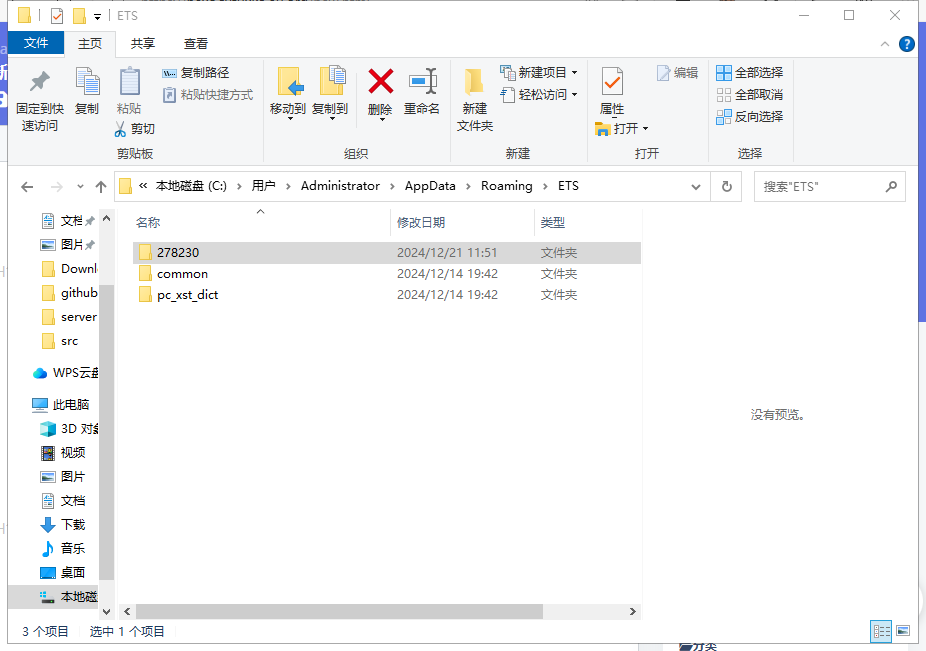
其中每段数字即代表着听说任务的编号,进入文件夹文件的结构是这样的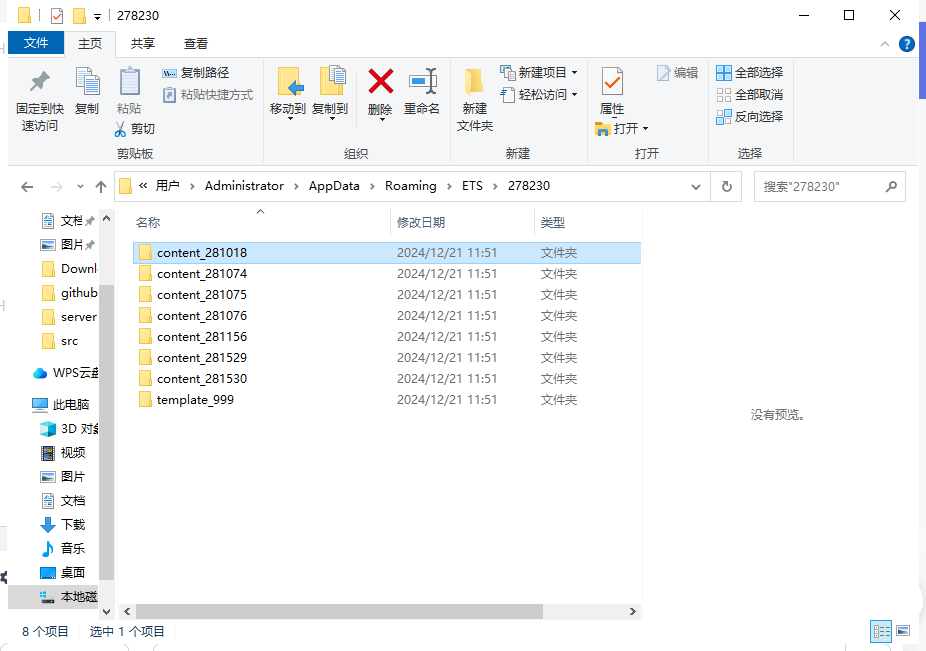
其中content+数字是分别对应的每道题目,编号最小的是第一大题,然后以此类推,然后template是题目信息(不是题目)是展示有多少道题目的,对应E听说的应该是这一部分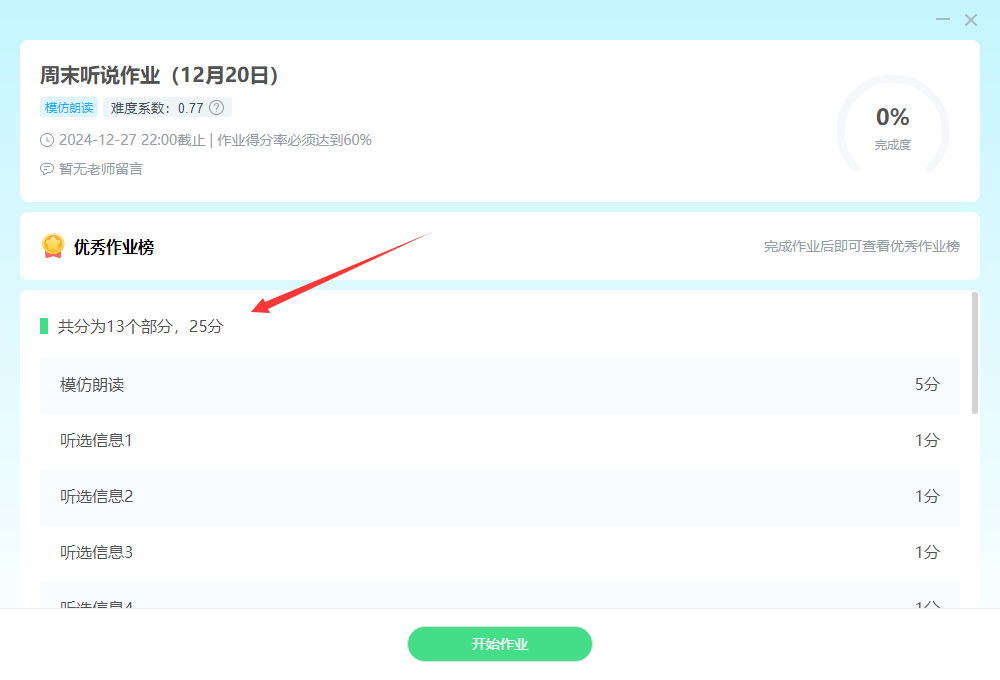
打开其中一个content文件夹,里面有info.json、content2.json、content.json以及material文件夹,其中info根据意思,是题目信息(不是题目)而content的两个文件就是我们所要的真正的题目以及答案了,然后material则是录音文件,不必理会,进一步查看,发现内容都挤在一行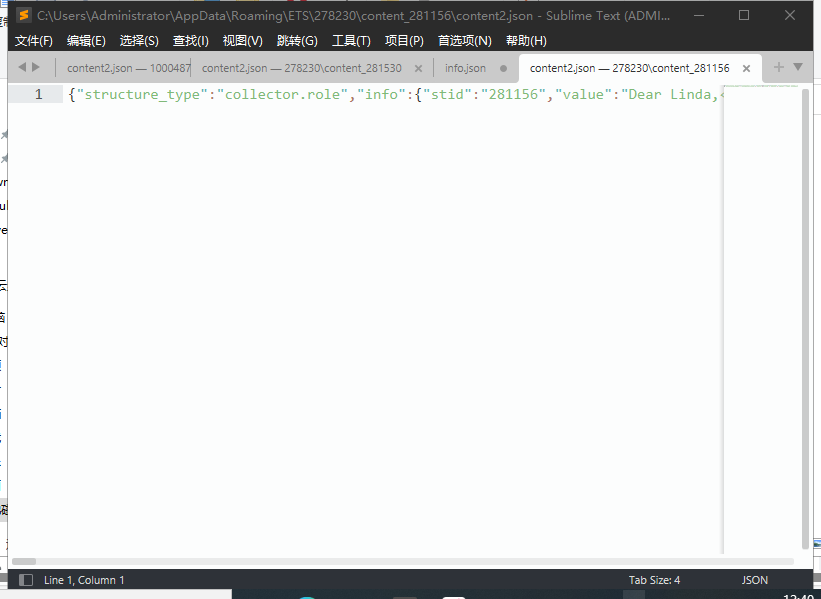
整理一下得到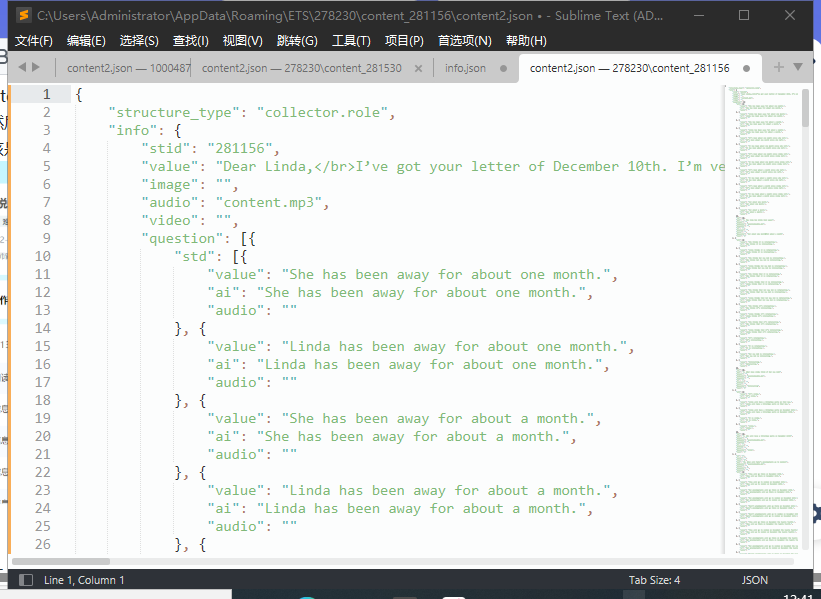
发现我们所要的题目便是ask标签内内容,而答案便是std标签中value中的内容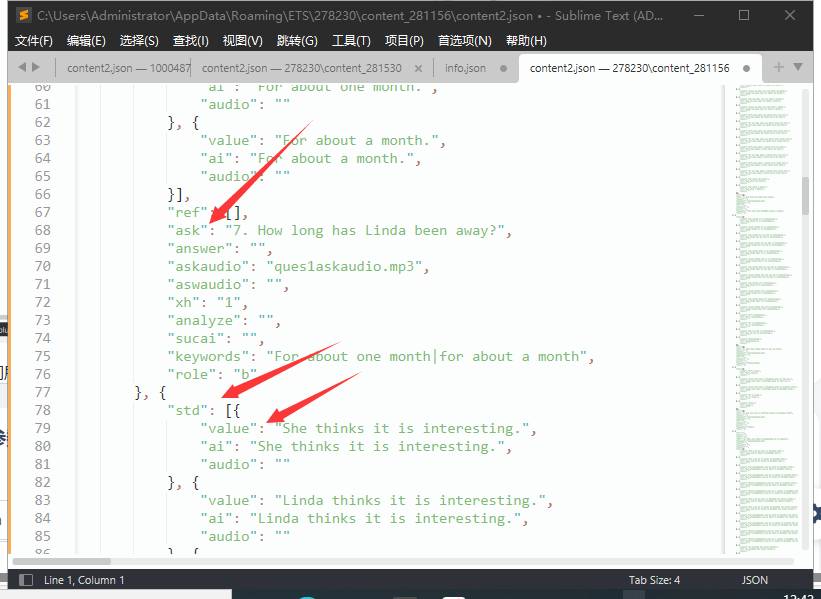
由此我们便可以制作python脚本获取答案了
至此目的已达到,脚本成功获取到答案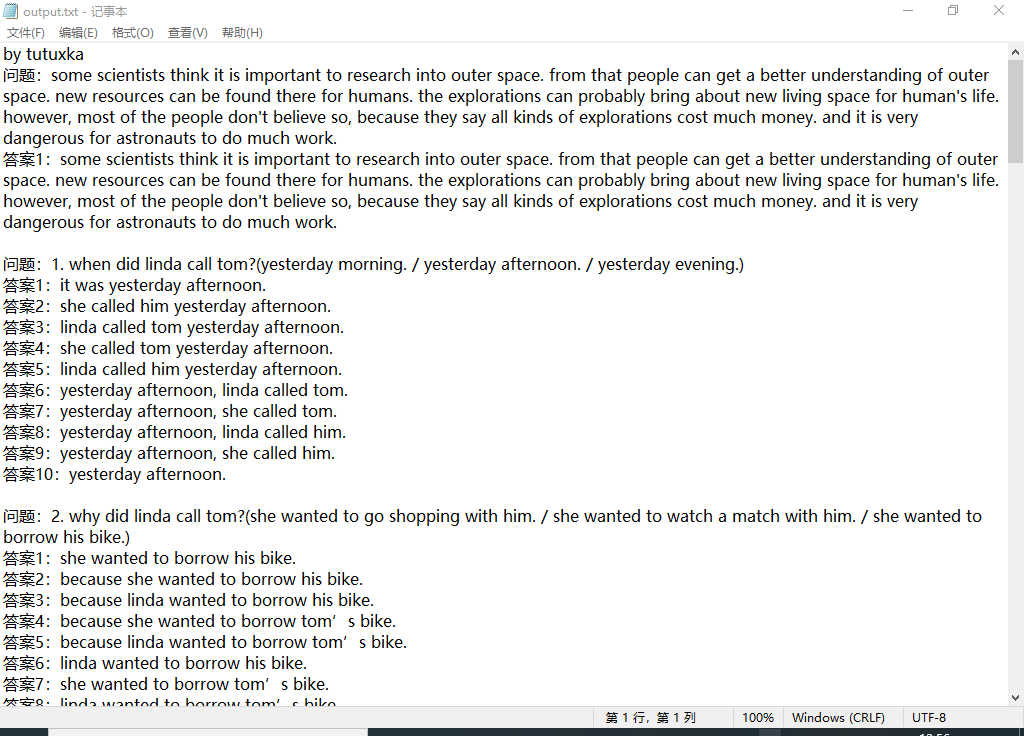
这里脚本就不放出了(写的太烂了)放出打包出来的软件吧https://www.123865.com/s/dVArVv-OZb3h?提取码:bmxX
评论